Overview
Anonymous Authors
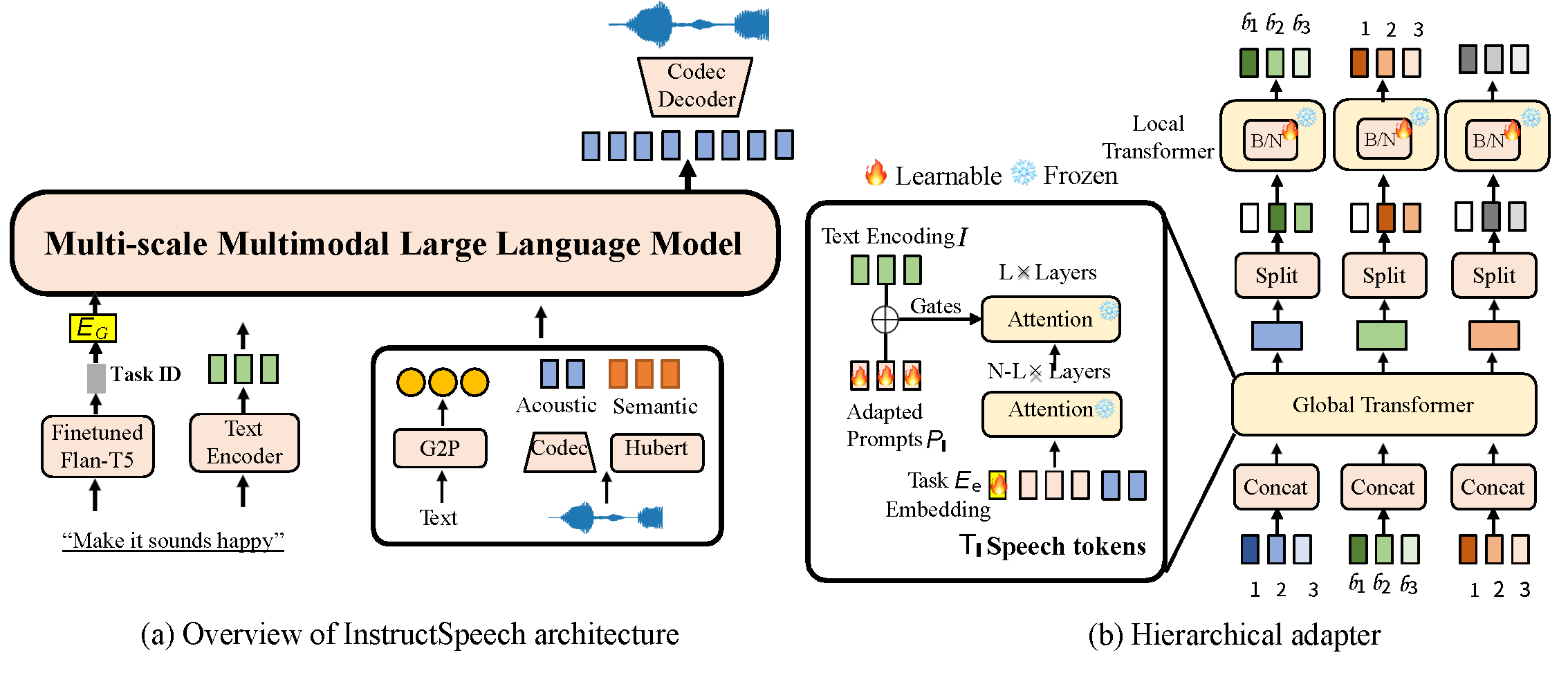
Abstract. Instruction-guided speech editing aims to follow the user’s natural language instruction to manipulate the semantic and acoustic attributes of a speech. In this work, we construct triplet paired data (instruction, input speech, output speech) to alleviate data scarcity and train a multi-task large language model named InstructSpeech. To mitigate the challenges of accurately executing user’s instructions, we 1) introduce the learned task embeddings with a fine-tuned Flan-T5-XL to guide the generation process towards the correct generative task; 2) include an extensive and diverse set of speech editing and speech processing tasks to enhance model capabilities; 3) investigate chainof- thought reasoning for free-form semantic content editing; and 4) propose a hierarchical adapter that effectively updates a small portion of parameters for generalization to new tasks. To assess instruction speech editing in greater depth, we introduce a benchmark evaluation with contrastive instruction-speech pretraining (CISP) to test the speech quality and instruction-speech alignment faithfulness. Experimental results demonstrate that InstructSpeech achieves state-of-the-art results in eleven tasks, for the first time unlocking the ability to edit the acoustic and semantic attributes of speech following a user’s instruction.
In this section, we provide the generated audio samples in style part with other systems on the acoustic attribute editing task.
| Instruction | Before Edit | Prompt | YourTTS Result | Result (ours) |
|---|---|---|---|---|
In this section, we provide the generated audio samples in energy part with other systems on the acoustic attribute editing task.
| Instruction | Transcription | Before Edit | Result (ours) |
|---|---|---|---|
In this section, we provide the generated audio samples in speed part with other systems on the acoustic attribute editing task.
| Instruction | Transcription | Before Edit | Base Result (ours) | Medium Result (ours) | Target Result (ours) |
|---|---|---|---|---|---|
In this section, we provide the generated audio samples in emotion part with other systems on the acoustic attribute editing task.
| Instruction | Before Edit | Prompt | YourTTS Result | Base Result (ours) | Medium Result (ours) | Target Result (ours) |
|---|---|---|---|---|---|---|
In this section, we provide the generated audio samples in region-based add.
| Input | Transcription | Target Transcription | Before Edit | Speechedit Result | A3t Result | Base Result (ours) | Medium Result (ours) | Large Result (ours) |
|---|---|---|---|---|---|---|---|---|
In this section, we provide the generated audio samples in region-based delete.
| Input | Transcription | Target Transcription | Before Edit | Speechedit Result | A3t Result | Base Result (ours) | Medium Result (ours) | Large Result (ours) |
|---|---|---|---|---|---|---|---|---|
In this section, we provide the generated audio samples in region-based edit.
| Input | Transcription | Target Transcription | Before Edit | Speechedit Result | A3t Result | Base Result (ours) | Medium Result (ours) | Large Result (ours) |
|---|---|---|---|---|---|---|---|---|
In this section, we provide the generated audio samples free_form region in add task.
| Instruction | Transcription | Target Transcription | Before Edit | Speechedit Result | A3t Result | Base Result (ours) | Medium Result (ours) | Large Result (ours) |
|---|---|---|---|---|---|---|---|---|
In this section, we provide the generated audio samples free_form region in delete task.
| Instruction | Transcription | Target Transcription | Before Edit | Speechedit Result | A3t Result | Base Result (ours) | Medium Result (ours) | Large Result (ours) |
|---|---|---|---|---|---|---|---|---|